
[Research Preview] Speculative Thinking: Large Models Mentoring Small Models for Efficient Reasoning
Large language models (LLMs) excel in complex reasoning tasks but often incur substantial computational costs, limiting their practicality in resource-constrained scenarios. Conversely, small models, while computationally efficient, frequently struggle with sophisticated reasoning and generalization. To bridge this gap, we propose a speculative thinking framework where large models serve as mentors to enhance the reasoning capabilities of smaller models efficiently.
- Our approach leverages the general reasoning patterns of the model’s inference process. By utilizing the reasoning capability of the larger model to assist the smaller model’s thinking process, we enhance the performance of the smaller model.
- The results demonstrate that our method effectively improves the accuracy of the 1.5B model from 82.2% to 86.4%, a 5.1% improvement.
- The decoding speed (Tokens/s) increases from 10.221 for the 32B model to 18.134, a 77.4% improvement.
Motivations
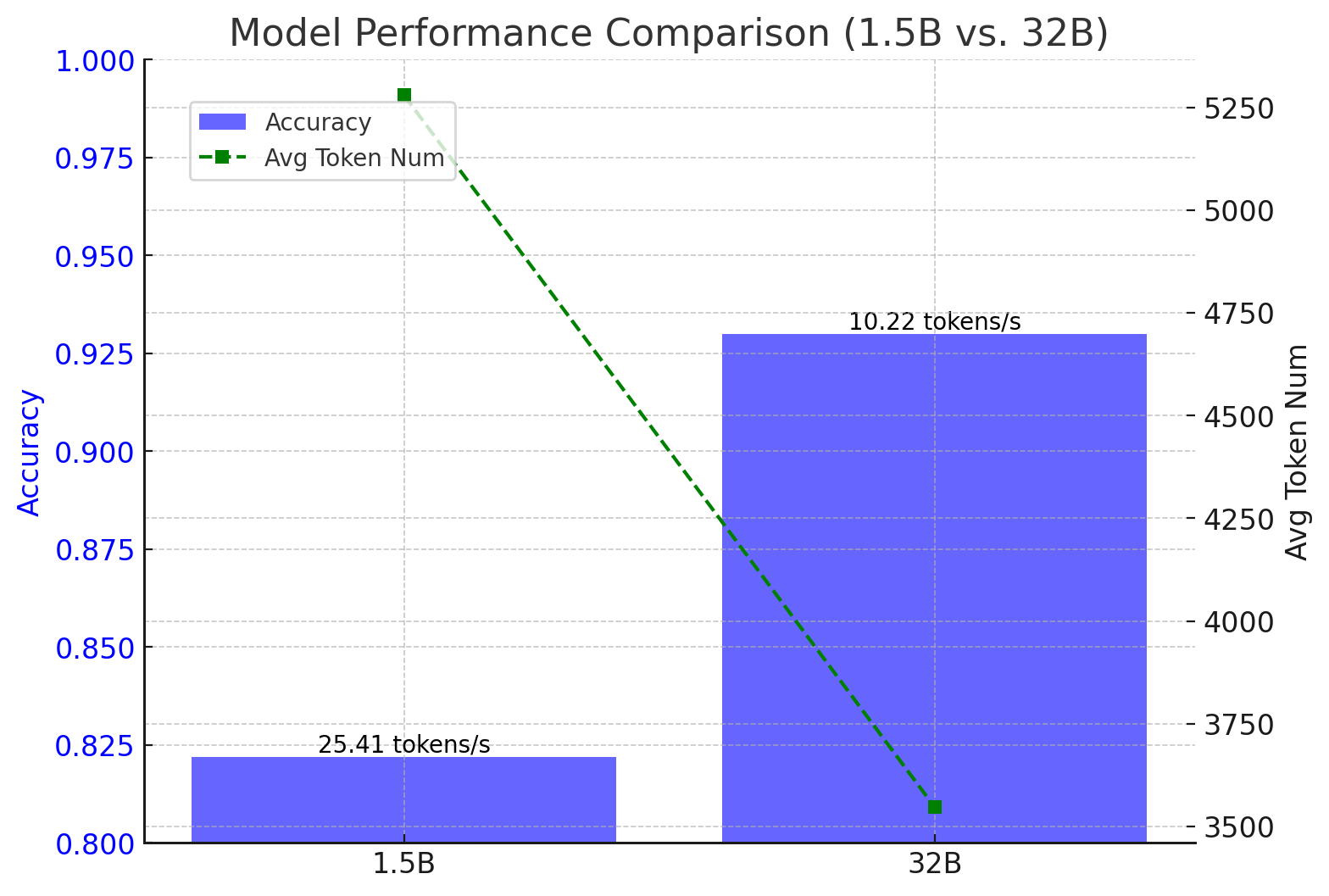
Small Model’s Responses are Much Longer
- We conduct a preliminary evaluation of DeepSeek-Distilled Qwen 2.5-1.5B and DeepSeek-Distilled Qwen 2.5-32B on the Math500 benchmark.
- We analyze the accuracy, average number of tokens per response, and tokens per second for both models.
- The results are summarized in the figure below.
- As observed, while DeepSeek-Distilled Qwen 2.5-1.5B has a lower accuracy and produces more tokens on average per response compared to DeepSeek-Distilled Qwen 2.5-32B , it generates responses at a faster speed.
- As observed, while DeepSeek-Distilled Qwen 2.5-1.5B has a lower accuracy and produces more tokens on average per response compared to DeepSeek-Distilled Qwen 2.5-32B , it generates responses at a faster speed.
Wrong Answer (Thoughts) is Much Longer
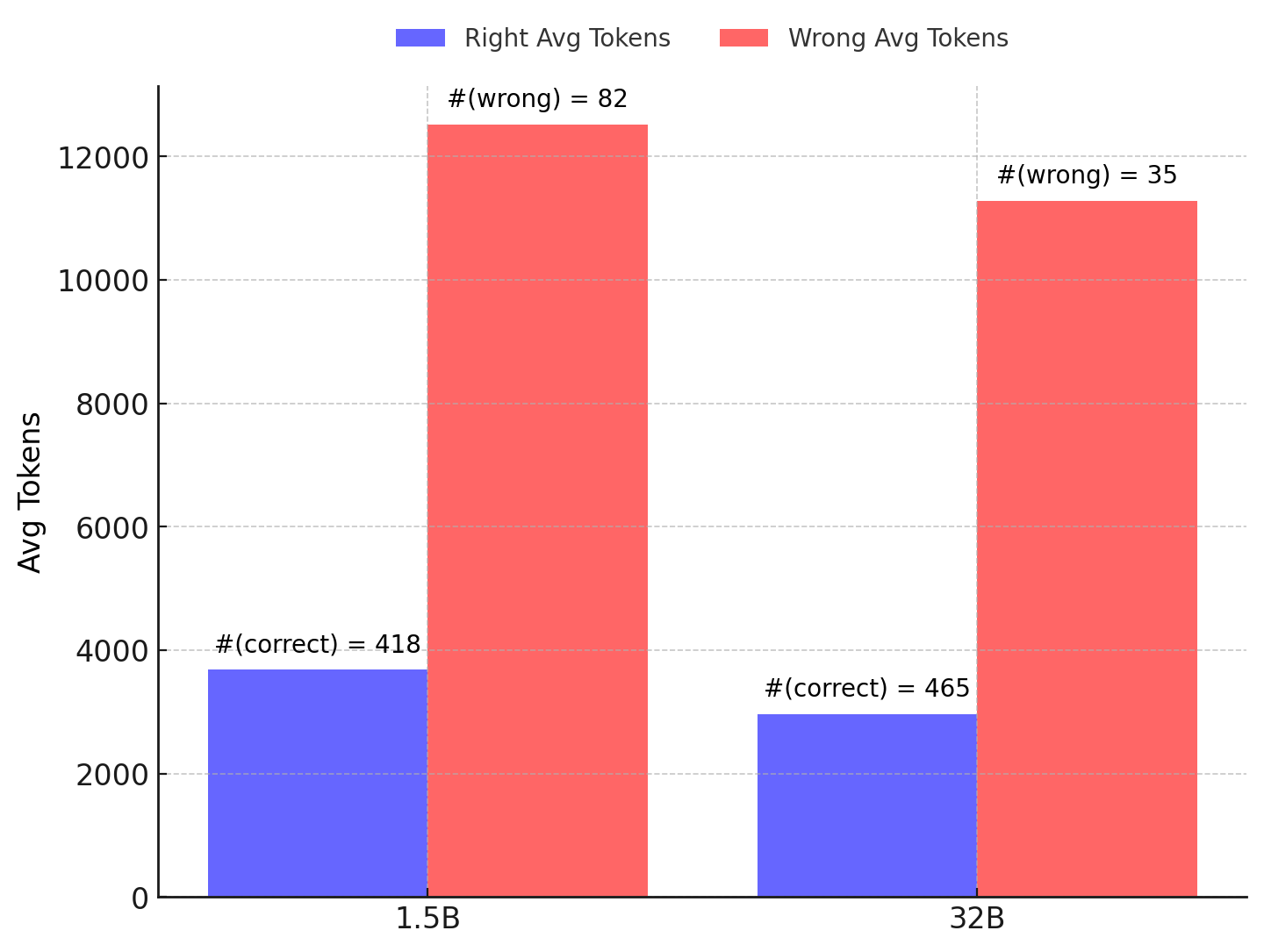
- We further analyze the response length differences between the 1.5B and 32B models in both correct and incorrect cases.
- Despite the significant difference in model size, the response length for correct answers is nearly identical between the two models. Similarly, the response length for incorrect answers is also consistent across both models.
- Additionally, we observe that incorrect responses tend to be significantly longer than correct responses.
Large model helps Small models
Analysis of Deepseek 1.5B Model’s Response
- First, we present a response generated by the 1.5B model. It can be observed that words such as “wait” typically appear after
\n\n. At the same time, we classify the sentences following\n\ninto two categories: negative vs. positive.- Negative sentences mainly contain words like “wait” and “verify”, indicating skepticism or reflection on the previous thought.
- Positive sentences mainly contain words like “yeah” and “confident”, representing affirmation of the previous thought.

Hypothesis on the Reasoning Process
- Based on this observation, we hypothesize that during inference, the reasoning model first generates a thought, followed by the
\n\ntoken. The model then analyzes this thought to determine whether to express skepticism or affirmation.
Utilizing the 32B Model to Assist the 1.5B Model
- Given our understanding of the reasoning model’s inference process, we propose leveraging the 32B model to assist the 1.5B model:
- The 32B model can evaluate the thought generated by the 1.5B model and classify it as negative or positive, thereby guiding the smaller model’s reasoning process.
- As observed in the previous section, while the 32B model has a slower generation speed, its average response length is shorter.
- Regardless of model size, the length of correct responses remains similar, while the length of incorrect responses is also consistent.
- By combining the strengths of the 32B and 1.5B models, we aim to improve the accuracy of the 1.5B model while simultaneously increasing the generation speed of the 32B model.
Method: Speculative Thinking
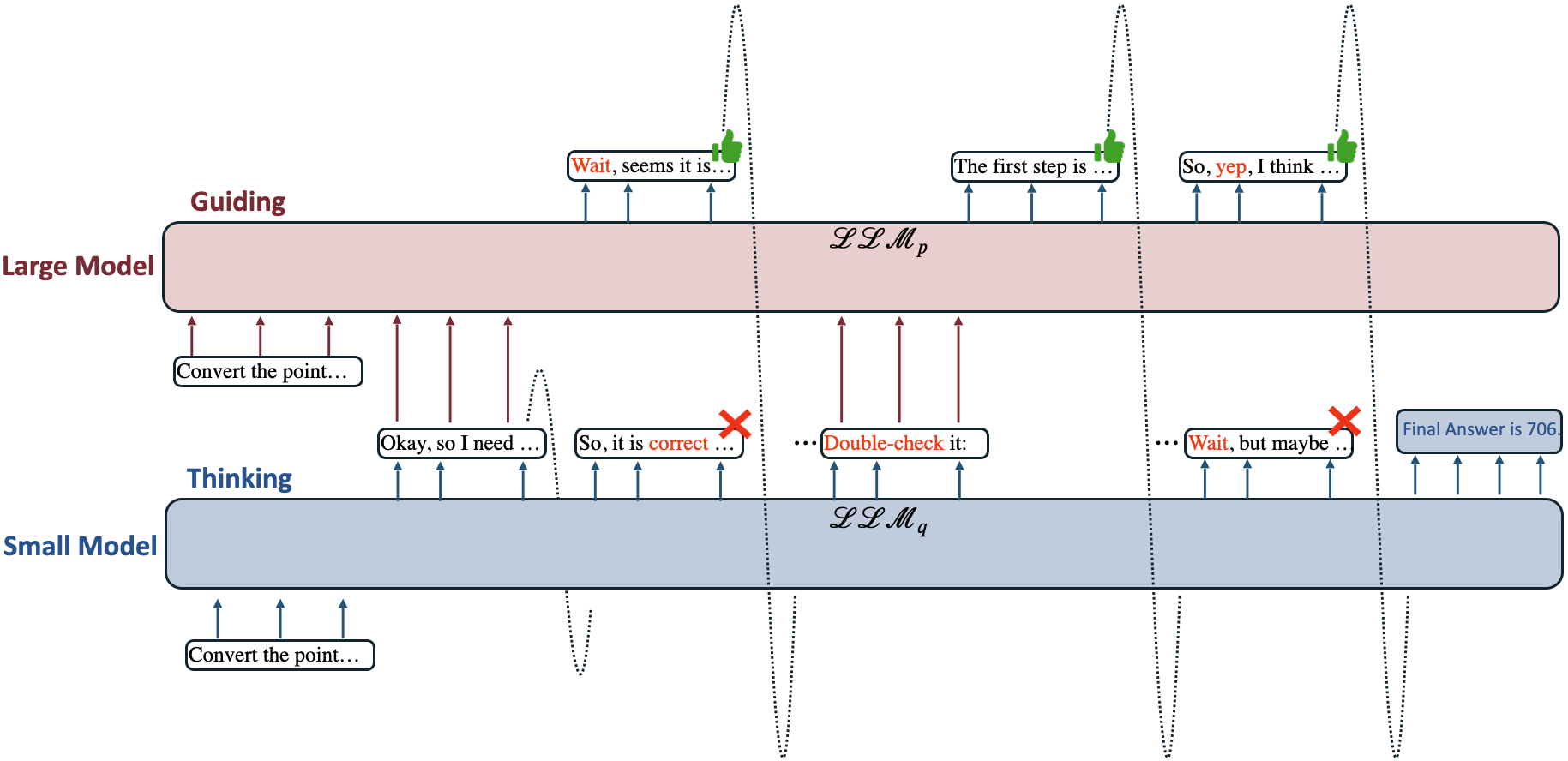
- Our method overview is illustrated in the figure.
- First, we define TRIGGER_TOKENS as
\n\n. When the next token generated by the 1.5B model contains TRIGGER_TOKENS, both the 1.5B model and the 32B model generate the next sentence independently. - We then classify the generated sentences from the 1.5B and 32B models as negative or positive:
- If both models generate sentences classified as either negative or positive, we directly adopt the sentence from the 1.5B model.
- If the classifications of the sentences from the 1.5B and 32B models differ, we adopt the sentence from the 32B model.
- The classification is determined based on word matching:
- Sentences containing ‘but’, ‘wait’, ‘alternatively’, ‘hold on’, ‘another’, ‘verify’, ‘think again’, ‘recap’, or ‘check’ are classified as negative.
- Sentences containing ‘yeah’, ‘yes’, ‘final answer’, or ‘confident’ are classified as positive.
- Sentences that contain none of these keywords are classified as neutral.
- First, we define TRIGGER_TOKENS as
Results
- We evaluate the performance of DeepSeek-32B, DeepSeek-1.5B, and our proposed speculative thinking decoding method on MATH500.
- The results indicate that our approach improves the accuracy of the 1.5B model from 82.2% to 86.4%. Additionally, the decoding speed (Tokens/s) increases from 10.221 for the 32B model to 18.134.
| Metric | deepseek-32b | deepseek-1.5b | Speculative Thinking | Improvement (%) |
|---|---|---|---|---|
| Accuracy | 93% | 82.2% | 86.4% | +5.1% |
| Tokens/s | 10.221 | 25.411 | 18.134 | +77.4% |
| Total Tokens | 3546.736 | 5279.928 | 4901.236 | |
| Wrong Avg Tokens | 11283.43 | 13936.08 | 11835.31 | |
| Wrong Num | 35 | 89 | 68 | |
| Right Avg Tokens | 2964.40 | 3405.48 | 3809.76 | |
| Correct Num | 465 | 411 | 432 |