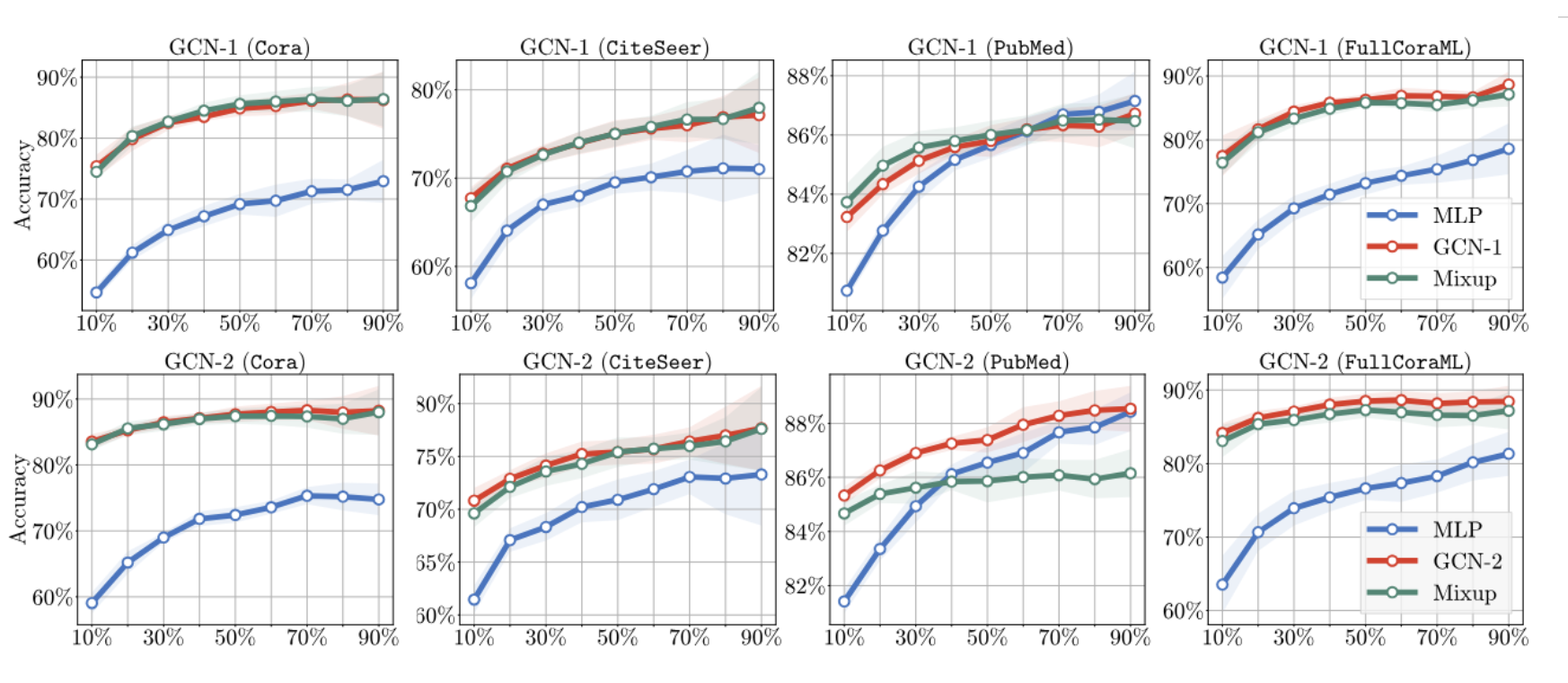
Graph Convolution ≈ Mixup
This might be one of my most liked papers that probably reveals the essence of graph convolution. It is published on TMLR and is selected as an Oral Presentation at LoG2024 TMLR Track. In this paper, we propose that graph convolution can be viewed as a specialized form of Mixup.
1. TL;DR
This paper builds the relationship between graph convolution and Mixup techniques.
- Graph convolution aggregates features from neighboring samples for a specific node (sample).
- Mixup generates new examples by averaging features and one-hot labels from multiple samples.
The two share one commonality that information aggregation from multiple samples. We reveal that, under two mild modifications, graph convolution can be viewed as a specialized form of Mixup that is applied during both the training and testing phases if we assign the target node's label to all its neighbors.
2. Graph Convolution ≈ Mixup
Graph Neural Networks have recently been recognized as the de facto state-of-the-art algorithm for graph learning. The core idea behind GNNs is neighbor aggregation, which involves combining the features of a node's neighbors. Specifically, for a target node with feature , one-hot label , and neighbor set , the graph convolution operation in GCN is essentially as follows:
In parallel, Mixup is proposed to train deep neural networks effectively, which also essentially generates a new sample by averaging the features and labels of multiple samples:
where / are the feature/label of sample . Mixup typically takes two data samples ().
The above two equations highlight a remarkable similarity between graph convolution and Mixup, i.e., the manipulation of data samples through averaging the features. This similarity prompts us to investigate the relationship between these two techniques as follows:
In this paper, we answer this question by establishing the connection between graph convolutions and Mixup, and further understanding the graph neural networks through the lens of Mixup. We show that graph convolutions are intrinsically equivalent to Mixup by rewriting as follows:
where , and and are the feature and label of the target node .
This above equation states that graph convolution is equivalent to Mixup if we assign the to all the neighbors of node in set .
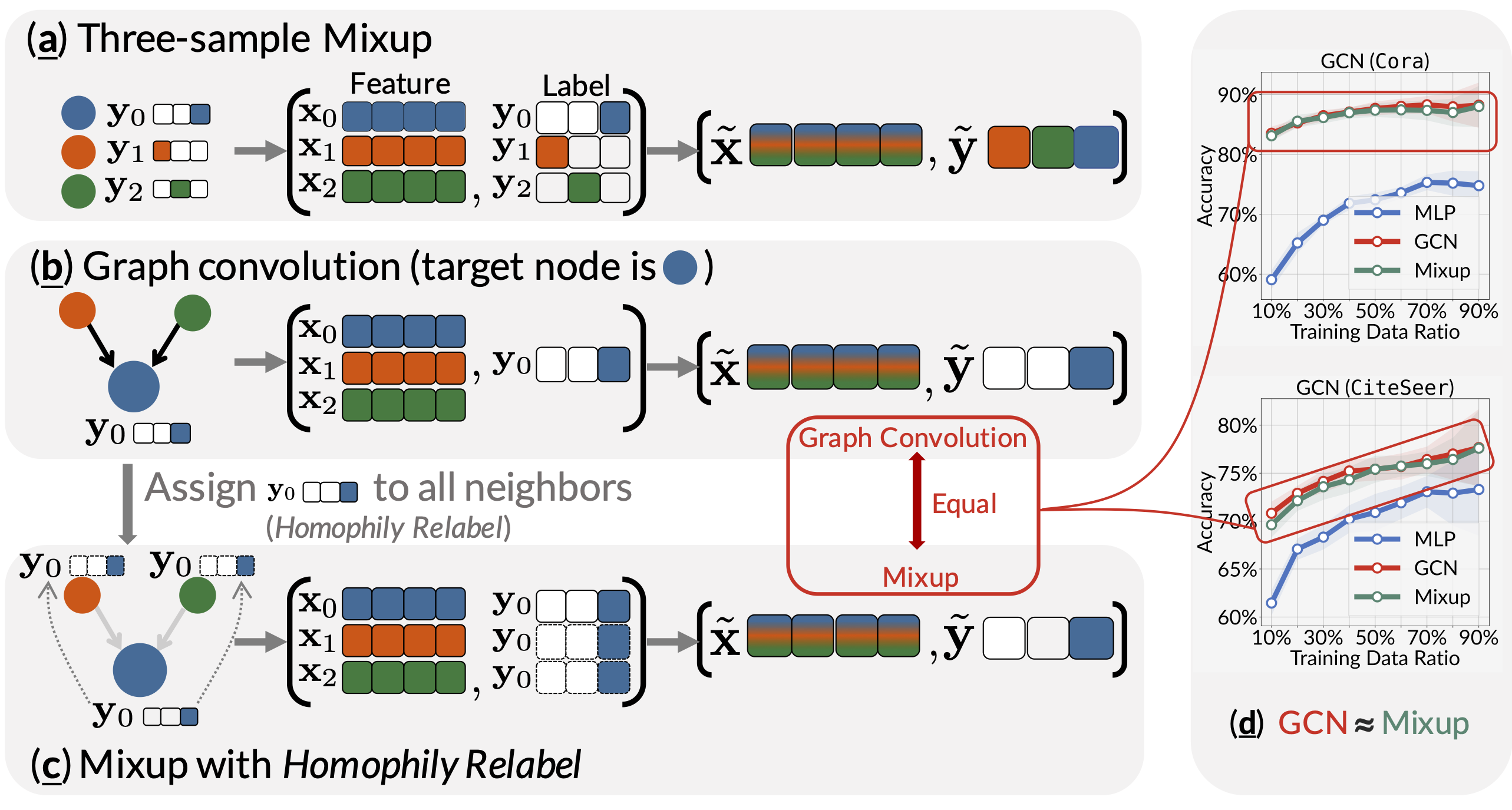
3. Experiments
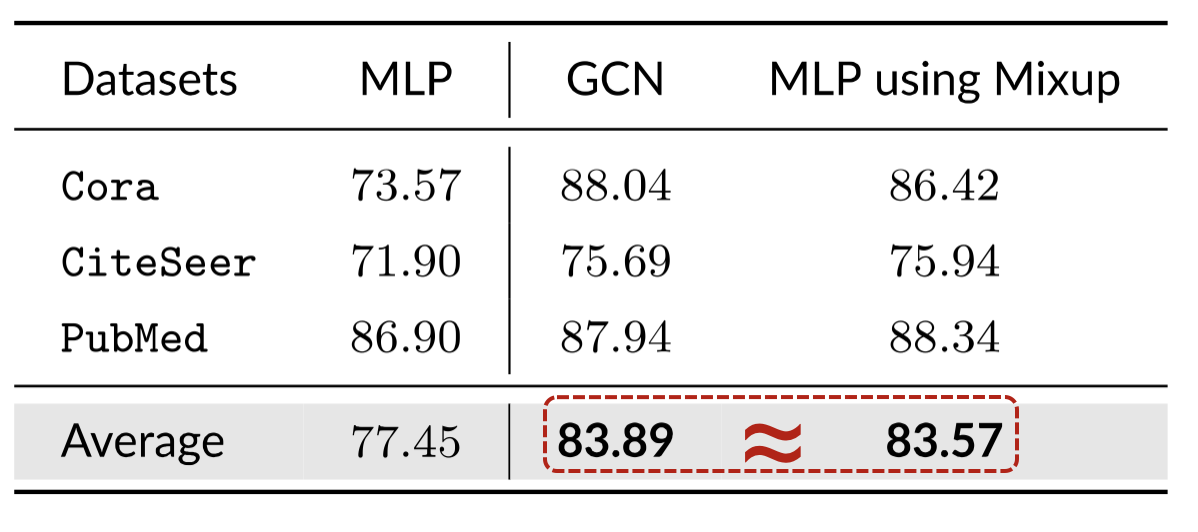
The experiments with the public split on Cora, CiteSeer, and Pubmed datasets and the results are shown in the following table. The results show that MLP with mixup can achieve comparable performance to the original GCN.
We experimented with different data splits of train/validation/test (the training data ratio span from ).
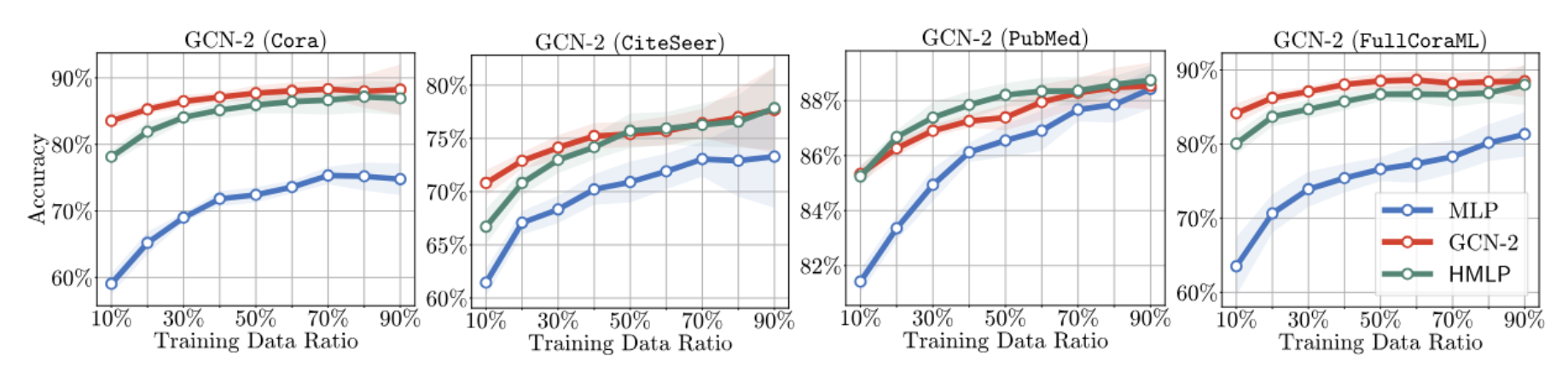
With the test-time mixup (details in the paper), the MLPs with mixup can achieve comparable performance to the original GCN.